
Microsoft SQL Server es
un sistema para la gestión de bases de datos producido por Microsoft basado en el modelo relacional. Sus lenguajes
para consultas son T-SQL y ANSI SQL. Microsoft SQL Server constituye
la alternativa de Microsoft a otros potentes sistemas gestores de bases de
datos como son Oracle, PostgreSQL o MySQL.
Objetivos del Diseño de SQL Server
SQL Server disminuye
el costo total de propiedad a través de características como administración multi-servidor y con una sola consola; ejecución y alerta de
trabajos basadas en eventos; seguridad integrada; y scripting administrativo. Esta
versión también libera al administrador de base de datos para aspectos más
sofisticados del trabajo al automatizar las tareas de rutina. Al combinar
estos poderosos servicios de administración con las nuevas
características de configuración automática, Microsoft SQL Server 7.0 es la
elección ideal de automatización de sucursales y aplicaciones de base de
datos insertadas.
Los clientes
invierten en sistemas de administración de bases de datos, en forma de
aplicaciones escritas para esa base de datos y la
educación que implica para la implementación y administración.
Esa inversión debe protegerse: a medida que el negocio crece,
la base de datos deberá crecer y manejar más datos, transacciones y usuarios.
Los clientes también desean proteger las inversiones a medida que escalan aplicaciones de base de
datos hacia equipos portátiles y sucursales.
Seguridad.
- Un único ID de login tanto para red como para la DB
para mejorar la seguridad y facilitar la administración.
- Password y encriptación de datos en red para
mejorar la seguridad.
- Encriptación de procedimientos almacenados para la
integridad y seguridad de código de aplicación.
- Interoperabilidad e integración con desktops.
- API estándard DB-Library totalmente soportada:
estándar ODBC Nivel 2 totalmente soportado como API nativa.
- Gateway Open Data Services (ODS) programable para
acceso transparente a fuentes de datos externas.
- Gateways de Microsoft y de terceros para fuentes de
datos relacionales y no-relacionales, incluyendo IBM DB2.
- Soporte de importantes estándares de mercado como
ANSI SQL-92, FIPS 127-2, XA, SNMP.
INSTALAR SQL SERVER 2005
Existen
diferentes versiones (ediciones) del producto, por lo que es un producto muy
versátil, que puede cumplir con las exigencias de cualquier empresa,
puede ser utilizado para gestionar bases de datos en un PC en modo local
a gestionar todo el sistema de información de grandes empresas pasando por
sistemas que requieran menos potencia y por sistemas móviles.
Actualmente
se utiliza más en entornos Cliente/servidor con equipos medianos y grandes.
Para realizar
este curso te recomendamos instalar la versión gratuita: Express.
Puedes descargarla desde la página web de Microsoft, desde el enlace para iniciar
descarga. Si quieres ver las diferentes ediciones y sus características
principales visita el siguiente avanzado.
Si la
instalación se realiza a partir del archivo descargado de Internet, la descarga
se empaqueta como un único ejecutable mediante una tecnología de instalación de
Microsoft llamada SFXCab. Al hacer doble clic en el .exe se inicia
automáticamente el proceso de instalación.
Tan sólo
deberemos seguir el asistente. Los puntos más importantes a tener en cuenta
son:
- Habilitar el SQL Server Management Studio en la
instalación (si no lo está por defecto) cuando nos pregunte qué
componentes deseamos instalar.
- Indicar que se trata de una Instancia
predeterminada.
Lo
ideal es que en este punto instales el programa, para ir probando lo que vayas
aprendiendo de aquí en adelante. Puedes realizar el siguiente Ejercicio
Instalación de SQL Server 2005. El videotutorial práctico de
instalación también te ayudará.
1.3. Entrada
al SQL Server Management Studio
Aunque
trabajemos en modo local, la entrada a la herramienta es la misma. Para empezar
entramos a través del acceso directo o a través de Inicio,
Programas, Microsoft SQL Server 2005, SQL Server Management Studio.
Lo primero
que deberemos hacer es establecer la conexión con el servidor:
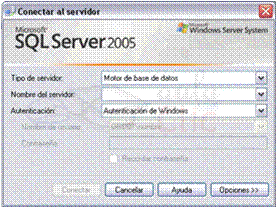
Seleccionamos
el nombre del servidor y pulsamos el botón Conectar. Se abrirá la
ventana inicial del SQL Server Management Studio (en adelante SSMS):

En la parte
izquierda tenemos abierto el panel Explorador de Objetos en el
que aparece debajo del nombre del servidor con el que estamos conectados una
serie de carpetas y objetos que forman parte del servidor.
En el panel de la derecha se muestra la zona de trabajo, que varía según lo que tengamos seleccionado en el Explorador de objetos, en este caso vemos el contenido de la carpeta que representa el servidor ord01.
En el panel de la derecha se muestra la zona de trabajo, que varía según lo que tengamos seleccionado en el Explorador de objetos, en este caso vemos el contenido de la carpeta que representa el servidor ord01.
En la parte
superior tenemos el menú de opciones y la barra de herramientas Estándar.
INTRODUCCIÓN A LA INTEGRIDAD DE LOS DATOS
Las tablas en
una base de datos SQL Server pueden incluir diferentes tipos de propiedades
para asegurar la integridad de los datos. Estas propiedades incluyen: tipos de
dato, definiciones NOT NULL, definiciones DEFAULT, propiedades IDENTITY,
restricciones, reglas, desencadenadores e índices. A continuación se presenta
una introducción de todos estos tipos de integridad de datos soportados por SQL
Server. Además, se discutirán los diferentes tipos de integridad de datos,
incluyendo integridad de entidad, integridad de dominio, integridad referencial
e integridad definida por el usuario.
Asegurar
la integridad de los datos
Asegurar la
integridad de los datos garantiza la calidad de los datos. Por ejemplo, suponga
que Ud. crea la tabla Clientes en su base de datos. Los valores en la columna
Cliente_ID deberían identificar unívocamente a cada cliente que es ingresado a
la tabla. Como resultado, si un cliente tiene un Cliente_ID de 438, ningún otro
cliente debería tener el valor Cliente_ID en 438. Luego, suponga que se ha
creado una columna Cliente_Eval que es utilizada para evaluar a cada cliente
con una calificación de 1 a 8. En este caso, la columna Cliente_Eval no deberá
aceptar un valor de 9 o cualquier otro valor que no esté entre 1 y 8. En ambos
casos, se deben usar métodos soportados por SQL Server para asegurar la
integridad de los datos.
 SQL Server
soporta varios métodos para asegurar la integridad de los datos, que incluyen:
tipos de dato, definiciones NOT NULL, definiciones DEFAULT, propiedades
IDENTITY, restricciones, reglas, desencadenadores e índices. Ya se han visto
algunos de estos métodos. Un breve resumen de ellos es incluido aquí a fin de
mostrar una visión comprehensiva de los distintos modos de asegurar la
integridad de los datos. Algunas de esta propiedades de la tablas, tales como
las definiciones NOT NULL y DEFAULT, son a veces consideradas tipos de
restricciones. Para los propósitos de este Kit, sin embargo, son tratadas de
forma separada.
SQL Server
soporta varios métodos para asegurar la integridad de los datos, que incluyen:
tipos de dato, definiciones NOT NULL, definiciones DEFAULT, propiedades
IDENTITY, restricciones, reglas, desencadenadores e índices. Ya se han visto
algunos de estos métodos. Un breve resumen de ellos es incluido aquí a fin de
mostrar una visión comprehensiva de los distintos modos de asegurar la
integridad de los datos. Algunas de esta propiedades de la tablas, tales como
las definiciones NOT NULL y DEFAULT, son a veces consideradas tipos de
restricciones. Para los propósitos de este Kit, sin embargo, son tratadas de
forma separada.
Tipos de
Dato
Un tipo de
dato es un atributo que especifica el tipo de dato (carácter, entero, binario,
etc.) que puede ser almacenado en una columna, parámetro o variable. SQL Server
provee de un conjunto de tipos de dato, aún cuando se pueden crear tipos de
dato definidos por el usuario que se crean sobre la base de tipos de dato
provisto por el SQL Server. Los tipos de dato provistos por el sistema definen
todos los tipos de dato que se pueden usar en SQL Server. Los tipos de dato
pueden ser utilizados para asegurar la integridad de los datos porque los datos
ingresados o modificados deben cumplir con el tipo de dato especificado para el
objeto correspondiente. Por ejemplo, no se puede almacenar el nombre de alguien
en una columna con un tipo de dato datetime, ya que esta columna solo aceptará
valores válidos de fecha y hora.
Definiciones
NOT NULL
La
anulabilidad de una columna determina si las filas en la tabla pueden contener
valores nulos para esa columna. Un valor nulo no es lo mismo que un cero, un
blanco o una cadena de caracteres de longitud cero. Un valor nulo significa que
no se ha ingresado ningún valor para esa columna o que el valor es desconocido
o indefinido. La anulabilidad de una columna se define cuando se crea o se
modifica una tabla. Si se usan columnas que permiten o no valores nulos, se
debería usar siempre las cláusula NULL y NOT NULL dada la
complejidad que tiene el SQL Server para manejar los valores nulos y no
prestarse a confusión. La cláusula NULL se usa si se permiten valores nulos en
la columna y la cláusula NOT NULL si no.
Definiciones
DEFAULT
Los valores
por defecto indican que valor será guardado en una columna si no se especifica
un valor para la columna cuando se inserta una fila. Las definiciones DEFAULT
pueden ser creadas cuando la tabla es creada (como parte de la definición de la
tabla) o pueden ser agregadas a una tabla existente. Cada columna en una tabla
puede contener una sola definición DEFAULT.
Propiedades
IDENTITY
Cada tabla
puede tener sólo una columna de identificación, la que contendrá una secuencia
de valores generados por el sistema que unívocamente identifican a cada fila de
la tabla. Las columnas de identificación contienen valores únicos dentro de la
tabla para la cual son definidas, no así con relación a otras tablas que pueden
contener esos valores en sus propias columnas de identificación. Esta situación
no es generalmente un problema, pero en los casos que así lo sea (por ejemplo
cuando diferentes tablas referidas a una misma entidad conceptual, como ser
clientes, son cargadas en diferentes servidores distribuidos en el mundo y
existe la posibilidad que en algún momento para generar reporte o consolidación
de información sean unidas) se pueden utilizar columnas ROWGUIDCOL como se vio
anteriormente.
Restricciones
(constraints)
Las
restricciones permiten definir el modo en que SQL Server automáticamente fuerza
la integridad de la base de datos. Las restricciones definen reglas indicando
los valores permitidos en las columnas y son el mecanismo estándar para
asegurar integridad. Usar restricciones es preferible a usar desencadenadores,
reglas o valores por defecto. El query optimizer (optimizador de consultas) de
SQL Server utiliza definiciones de restricciones para construir planes de
ejecución de consultas de alto rendimiento.
.jpg)
Reglas
(rules)
Las reglas
son capacidades mantenidas por compatibilidad con versiones anteriores de SQL
Server, que realizan algunas de las mismas funcionalidades que las
restricciones CHECK. Las restricciones CHECK son el modo preferido y estándar
de restringir valores para una columna. Las restricciones CHECK, por otro lado,
son mas concisas que las reglas; se puede aplicar solo una regla por columna
mientras que se pueden aplicar múltiples restricciones CHECK. Las restricciones
CHECK son especificadas como parte del comando CREATE TABLE, mientras que las
reglas son creadas como objetos separados y luego vinculadas a la columna.
Se utiliza el
comando CREATE RULE para crear una regla, y luego se debe utilizar el
procedimiento almacenado sp_bindrule para vincular la regla a una columna o a
un tipo de dato definido por el usuario.
Desencadenadores
Los
desencadenadores son una clase especial de procedimientos almacenados que son
definidos para ser ejecutados automáticamente cuando es ejecutado un comando
UPDATE, INSERT o DELETE sobre una tabla o una vista. Los desencadenadores son
poderosas herramientas que pueden ser utilizados para aplicar las reglas de
negocio de manera automática en el momento en que los datos son modificados.
Los desencadenadores pueden comprender el control lógico que realizan loas
restricciones, valores por defecto, y reglas de SQL Server (aún cuando es recomendable
usar restricciones y valores por defecto antes que desencadenadores en la
medida que respondan a todas las necesidades de control de integridad de
datos).
Indices
Un índice es
una estructura que ordena los datos de una o más columnas en una tabla de base
de datos. Un índice provee de punteros a los valores de los datos almacenados
en columnas especificadas de una tabla y luego ordena esos punteros de acuerdo
al orden que se especifique. Las bases de datos utilizan los índices del mismos
modo que se utilizan los índices de un libro: se busca en el índice para
encontrar un determinado valor y luego se sigue un puntero a la fila que
contiene ese valor. Un índice con clave única asegura la unicidad en la
columna.
TIPOS DE INTEGRIDAD DE DATOS
SQL Server
soporta cuatro tipos de integridad de datos: integridad de entidad, integridad
de dominio, integridad referencial e integridad definida por el usuario.
Integridad
de entidad
La integridad
de entidad define una fila como una única instancia de una entidad para una
tabla en particular. La integridad de entidad asegura la integridad de la
columna de identificación o la clave primaria de una tabla ( a través de
índices, estricciones UNIQUE, restricciones PRIMARY KEY, o propiedades
IDENTITY).
Integridad
de dominio
La integridad
de dominio es la validación de las entradas en una determinada columna. Se
puede asegurar la integridad de dominio restringiendo el tipo (a través de
tipos de datos), el formato (a través de las restricciones CHECK y de las
reglas), o el rango de valores posibles ( a través de restricciones FOREIGN
KEY, restricciones CHECK, definiciones DEFAULT, definiciones NOT NULL, y
reglas)
Integridad
referencial
La integridad
referencial preserva las relaciones definidas entre tablas, cuando se entran,
modifican o borran registros. En SQL Server, la integridad referencial esta
basada en interrelaciones entre claves ajenas y claves primarias o entre claves
ajenas y claves únicas (a través de la restricciones FOREIGN KEY y
CHECK). La integridad referencial asegura que los valores de las claves son
consistentes a través de distintas tablas. Tal consistencia requiere que no
existan referencia a valores inexistentes y que, si un valor clave cambia,
todas las referencias cambien consistentemente a lo largo de la base de datos.
Cuando se
fuerza la integridad referencial, SQL Server previene a los usuarios de
realizar lo siguiente:
· Agregar
registros a una tabla relacionada si no hay registros asociados en la
correspondiente tabla primaria.
· Cambiar
valores en la tabla primaria que resulten en registros huérfanos en las tablas
relacionadas.
· Borrar
registros desde una tabla primaria si existen registros relacionados en la
tabla ajena.
Por ejemplo,
con las tablas Ventas y Títulos en la base de datos Pubs, la integridad
referencial está basada sobre las relaciones entre la clave ajena (tit_ID) en
la tabla ventas y la clave primaria (tit_ID) en la tabla Titulos, como se
muestra en la Figura.

Figura 1: Integridad referencial entre la tabla Ventas y la tabla Titulos
Integridad
definida por el usuario
La integridad
definida por el usuario permite definir reglas de negocios específicas que no
caigan dentro de alguna de las categorías anteriores. Todas las categorías
soportan integridad definida por el usuario (todas las restricciones a nivel
columna y a nivel tabla en el comando CREATE TABLE, procedimientos almacenados
y desencadenadores)
Implementar
restricciones de integridad
Una
restricción es una propiedad asignada a una tabla o a una columna que previene
que datos inválidos sean grabados en la o las columnas especificadas. Por
ejemplo, una restricción UNIQUE o PRIMARY KEY previene de
inserciones de valores que dupliquen un valor existente, mientras que las
restricciones CHECK previenen de inserciones que no igualen una condición de
búsqueda, y una restricción FOREIGN KEY asegura la consistencia de la relación
entre dos tablas.
Introducción
a las restricciones de integridad
La
restricciones permiten definir la forma en que SQL Server automáticamente
asegurará la integridad de la base de datos. Las restricciones definen reglas
en base a los valores permitidos en las columnas y son los mecanismos estándar
para asegurar la integridad. Se deberían usar restricciones en vez de
desencadenadores, procedimientos almacenados, valores por defecto o reglas.
Las
restricciones pueden ser restricciones de columnas o de tablas:
· Una
restricción de columna es especificada como parte de la definición de la
columna y se aplica solo a esta columna.
· Una
restricción de tabla es declarada independientemente de las definiciones de la
columna y se puede aplicar a mas de una columna en la tabla.
Las
restricciones de tabla deben ser usadas cuando mas de una columna se incluye en
la formulación de la condición. Por ejemplo, si una tabla tiene dos o mas
columnas en la clave primaria, se debe usar una restricción de tabla para
incluirlas a todas en la clave primaria. Supongamos una tabla que registra
eventos que suceden en una computadora de una fábrica. Dicha tabla registra
eventos de diferente tipo que pueden suceder al mismo tiempo, pero no pueden
suceder dos eventos del mismo tipo al mismo tiempo. Esta regla puede ser
forzada incluyendo a ambas columnas; tipos de eventos y tiempo, en una clave
primaria de dos columnas, como se muestra en el siguiente comando CREATE TABLE:
CREATE TABLE
Procesos
(
TipoEvento int,
TiempoEvento datetime,
LugarEvento char(50),
DescripEvento char(1024),
CONSTRAINT event_key PRIMARY KEY (TipoEvento, TiempoEvento)
)
(
TipoEvento int,
TiempoEvento datetime,
LugarEvento char(50),
DescripEvento char(1024),
CONSTRAINT event_key PRIMARY KEY (TipoEvento, TiempoEvento)
)
SQL Server
soporta cuatro clases principales de restricciones: PRIMARY KEY, UNIQUE,
FOREIGN KEY y CHECK.
Restricciones
PRIMARY KEY
Una tabla
usualmente tiene una columna (o una combinación de columnas) que identifica
unívocamente cada fila de la tabla. Esta columna (o columnas) son llamadas
“clave primaria” de la tabla y aseguran la integridad de la entidad de la
tabla. Se puede crear una clave primaria usando la restricción PRIMARY KEY
cuando se crea o modifica la tabla.
Una tabla
puede tener solo una restricción PRIMARY KEY, y ninguna columna que participa
de la clave primaria puede aceptar nulos. Cuando se especifica una restricción
PRIMARY KEY para una tabla, SQL Server 2000 asegura la unicidad de los datos
creando un índice principal para las columnas de la clave primaria. Este índice
permite, además, un acceso rápido a las filas cuando la clave primaria se usa
para formular consultas.
Si se define
la restricción PRIMARY KEY para mas de una columna, los valores se pueden
duplicar para una columna, pero cada combinación de valores para todas las
columnas de la clave principal de una fila debe ser única para toda la tabla.
La figura muestra como las columnas Autor_ID y Titulo_ID de la tabla
TituloAutor forman una restricción PRIMARY KEY, la que asegura que las
combinaciones Autor_ID Titulo_ID son únicas.
